Vertex AI Searchグラウンディングを理解する¶
Vertex AI Searchグラウンディングツールは、AIエージェントがプライベートな企業ドキュメントやデータリポジトリの情報にアクセスできるようにする、Agent Development Kit (ADK) の強力な機能です。エージェントをインデックス化された企業コンテンツに接続することで、組織の知識ベースに基づいた回答をユーザーに提供できます。
この機能は、社内ドキュメント、ポリシー、研究論文、またはVertex AI Searchデータストアにインデックス化された独自のコンテンツからの情報が必要な、企業固有のクエリに特に役立ちます。エージェントが知識ベースからの情報が必要であると判断すると、インデックス化されたドキュメントを自動的に検索し、適切な帰属表示とともに結果を応答に組み込みます。
学習内容¶
このガイドでは、次の内容を学びます。
- クイックセットアップ: Vertex AI Search対応エージェントを一から作成して実行する方法
- グラウンディングアーキテクチャ: 企業ドキュメントグラウンディングのデータフローと技術プロセス
- 応答構造: グラウンディングされた応答とそのメタデータを解釈する方法
- ベストプラクティス: 引用とドキュメント参照をユーザーに表示するためのガイドライン
Vertex AI Searchグラウンディングクイックスタート¶
このクイックスタートでは、Vertex AI Searchグラウンディング機能を持つADKエージェントの作成について説明します。このクイックスタートは、Python 3.10+とターミナルアクセスが可能なローカルIDE (VS CodeまたはPyCharmなど) を想定しています。
1. Vertex AI Searchの準備¶
Vertex AI SearchデータストアとデータストアIDをすでにお持ちの場合は、このセクションをスキップできます。そうでない場合は、カスタム検索の開始の手順に従い、データストアの作成の最後まで、非構造化データタブを選択してください。この指示により、Alphabet投資家サイトの決算報告書PDFを含むサンプルデータストアが構築されます。
データストアの作成セクションを完了したら、データストアを開き、作成したデータストアを選択して、データストアIDを見つけます。

このデータストアIDは後で使用するため、メモしておきます。
2. 環境設定とADKのインストール¶
仮想環境の作成とアクティブ化:
# 作成
python -m venv .venv
# アクティブ化 (新しいターミナルごとに)
# macOS/Linux: source .venv/bin/activate
# Windows CMD: .venv\Scripts\activate.bat
# Windows PowerShell: .venv\Scripts\Activate.ps1
ADKのインストール:
3. エージェントプロジェクトを作成する¶
プロジェクトディレクトリの下で、次のコマンドを実行します。
agent.pyを編集する¶
次のコードをagent.pyにコピーして貼り付け、Configuration部分のYOUR_PROJECT_IDとYOUR_DATASTORE_IDをそれぞれプロジェクトIDとデータストアIDに置き換えます。
from google.adk.agents import Agent
from google.adk.tools import VertexAiSearchTool
# 構成
DATASTORE_ID = "projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID"
root_agent = Agent(
name="vertex_search_agent",
model="gemini-2.5-flash",
instruction="Vertex AI Searchを使用して社内ドキュメントから情報を検索し、質問に回答します。可能な場合は常に情報源を引用してください。",
description="Vertex AI Search機能を備えたエンタープライズドキュメント検索アシスタント",
tools=[VertexAiSearchTool(data_store_id=DATASTORE_ID)]
)
これで、次のディレクトリ構造になります。
4. 認証設定¶
注: Vertex AI SearchにはGoogle Cloud Platform (Vertex AI) の認証が必要です。Google AI Studioはこのツールではサポートされていません。
- gcloud CLIをセットアップします。
- ターミナルから
gcloud auth loginを実行してGoogle Cloudに認証します。 -
.envファイルを開き、次のコードをコピーして貼り付け、プロジェクトIDとロケーションを更新します。
5. エージェントを実行する¶
エージェントと対話する方法は複数あります。
次のコマンドを実行して開発UIを起動します。
Windowsユーザーへの注意
_make_subprocess_transport NotImplementedErrorが発生した場合は、代わりにadk web --no-reloadを使用することを検討してください。
ステップ1: 提供されたURL (通常はhttp://localhost:8000またはhttp://127.0.0.1:8000) をブラウザで直接開きます。
ステップ2. UIの左上隅にあるドロップダウンでエージェントを選択できます。「vertex_search_agent」を選択します。
トラブルシューティング
ドロップダウンメニューに「vertex_search_agent」が表示されない場合は、エージェントフォルダの親フォルダ (つまり、vertex_search_agentの親フォルダ) でadk webを実行していることを確認してください。
ステップ3. 次に、テキストボックスを使用してエージェントとチャットできます。
📝 試してみるプロンプトの例¶
これらの質問で、エージェントがAlphabetレポートから情報を取得するために実際にVertex AI Searchを呼び出していることを確認できます。
- 2022年第1四半期のGoogle Cloudの収益はいくらですか?
- YouTubeについてはどうですか?

ADKを使用してVertex AI Searchエージェントの作成と対話に成功しました!
Vertex AI Searchでのグラウンディングの仕組み¶
Vertex AI Searchでのグラウンディングは、エージェントを組織のインデックス化されたドキュメントとデータに接続し、プライベートな企業コンテンツに基づいて正確な応答を生成できるようにするプロセスです。ユーザーのプロンプトが内部の知識ベースからの情報を必要とする場合、エージェントの基盤となるLLMは、インデックス化されたドキュメントから関連する事実を見つけるためにVertexAiSearchToolを呼び出すことをインテリジェントに決定します。
データフロー図¶
この図は、ユーザーのクエリがグラウンディングされた応答になるまでのステップバイステップのプロセスを示しています。
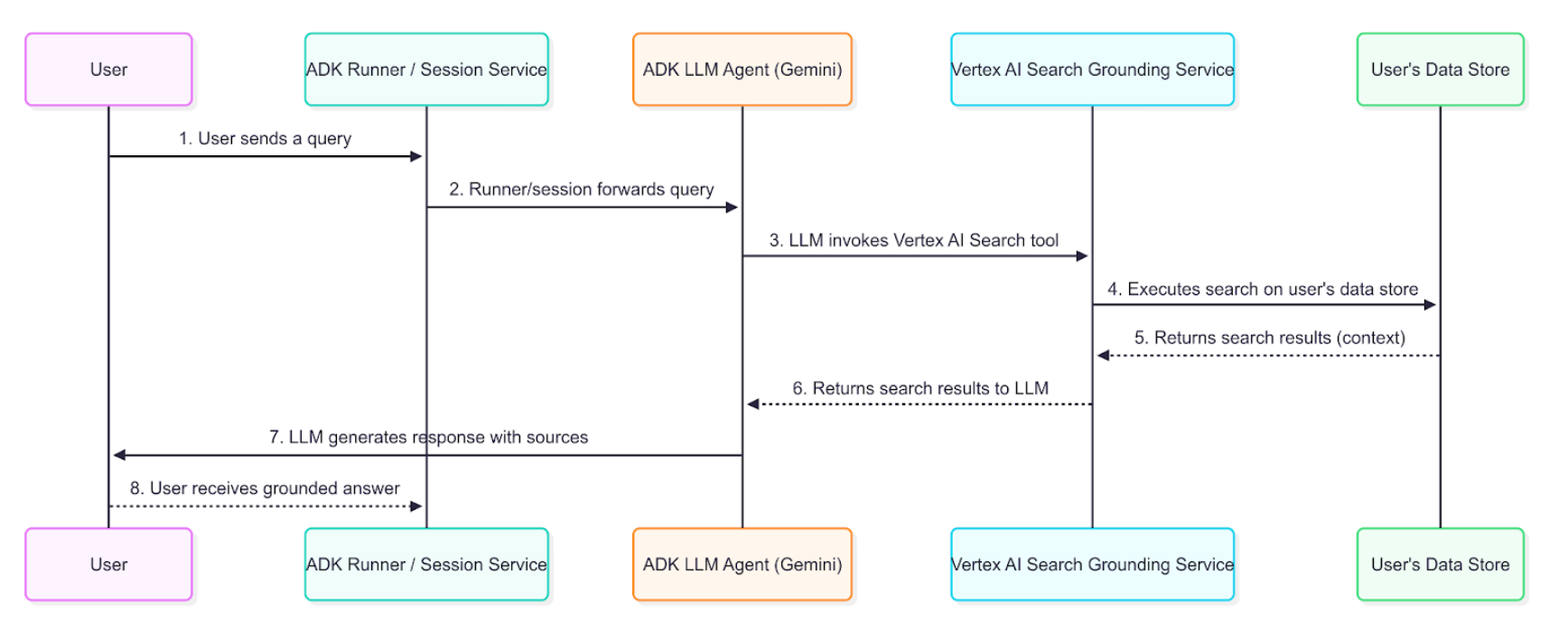
詳細な説明¶
グラウンディングエージェントは、図に示されているデータフローを使用して、企業情報を取得、処理し、ユーザーに提示される最終的な回答に組み込みます。
-
ユーザーのクエリ: エンドユーザーは、社内ドキュメントまたは企業データに関する質問をして、エージェントと対話します。
-
ADKのオーケストレーション: Agent Development Kitは、エージェントの動作をオーケストレーションし、ユーザーのメッセージをエージェントのコアに渡します。
-
LLM分析とツール呼び出し: エージェントのLLM (例: Geminiモデル) はプロンプトを分析します。インデックス化されたドキュメントからの情報が必要であると判断した場合、VertexAiSearchToolを呼び出すことでグラウンディングメカニズムをトリガーします。これは、会社ポリシー、技術文書、または独自の調査に関するクエリに回答するのに理想的です。
-
Vertex AI Searchサービスとの対話: VertexAiSearchToolは、構成されたVertex AI Searchデータストアと対話します。このデータストアには、インデックス化された企業ドキュメントが含まれています。サービスは、プライベートなコンテンツに対して検索クエリを作成し、実行します。
-
ドキュメントの取得とランキング: Vertex AI Searchは、意味的類似性と関連性スコアリングに基づいて、データストアから最も関連性の高いドキュメントチャンクを取得し、ランク付けします。
-
コンテキストの注入: 検索サービスは、最終的な応答が生成される前に、取得されたドキュメントスニペットをモデルのコンテキストに統合します。この重要なステップにより、モデルは組織の事実データについて「推論」できます。
-
グラウンディングされた応答の生成: 関連する企業コンテンツによって情報が提供されたLLMは、ドキュメントから取得された情報を取り入れた応答を生成します。
-
情報源ととも応答の提示: ADKは、必要な情報源ドキュメントの参照とgroundingMetadataを含む最終的なグラウンディングされた応答を受け取り、帰属表示とともにユーザーに提示します。これにより、エンドユーザーは企業の情報源に対して情報を検証できます。
Vertex AI Search応答でグラウンディングを理解する¶
エージェントがVertex AI Searchを使用して応答をグラウンディングする場合、最終的なテキスト回答と、その回答を生成するために使用されたドキュメントに関するメタデータを含む詳細な情報が返されます。このメタデータは、応答を検証し、企業の情報源に帰属表示を提供するために非常に重要です。
グラウンディングされた応答の例¶
以下は、企業ドキュメントに対するグラウンディングされたクエリ後にモデルによって返されるコンテンツオブジェクトの例です。
最終回答テキスト:
"医療書記モデルの開発は、主に医療文書の複雑な性質、関連する機密データ、臨床ワークフローの厳しい要件により、いくつかの重大な課題を抱えています。主な課題は次のとおりです。**正確性と信頼性:** 医療文書は、誤診、不適切な治療、法的責任につながる可能性があるため、極めて高いレベルの正確性が求められます。AIモデルが、微妙な医療言語を確実に捉え、主観的な情報と客観的な情報を区別し、医師と患者のやり取りを正確に書き起こすことができるようにすることは、大きなハードルです。**自然言語理解 (NLU) と音声認識:** 医療会話はしばしば迅速で、高度に専門化された専門用語、頭字語、略語が含まれており、さまざまなアクセントや話し方の個人によって話されることがあります... [応答はプライバシー、統合、技術的課題の詳細な分析で続きます]"
グラウンディングメタデータスニペット:
これが受信するグラウンディングメタデータです。adk webでは、これをResponseタブで見つけることができます。
{
"groundingMetadata": {
"groundingChunks": [
{
"document": {
"title": "AI in Medical Scribing: Technical Challenges",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-medical-scribe-ai-tech-challenges",
"id": "doc-medical-scribe-ai-tech-challenges"
}
},
{
"document": {
"title": "Regulatory and Ethical Hurdles for AI in Healthcare",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-ai-healthcare-ethics",
"id": "doc-ai-healthcare-ethics"
}
}
// ... その他のドキュメント
],
"groundingSupports": [
{
"groundingChunkIndices": [0, 1],
"segment": {
"endIndex": 637,
"startIndex": 433,
"text": "AIモデルが微妙な医療言語を確実に捉えることができるようにすること..."
}
}
// ... テキストセグメントをソースドキュメントにリンクする追加のサポート
],
"retrievalQueries": [
"challenges in natural language processing medical domain",
"AI medical scribe challenges",
"difficulties in developing AI for medical scribes"
// ... 実行された追加の検索クエリ
]
}
}
応答の解釈方法¶
メタデータは、モデルによって生成されたテキストと、それをサポートする企業ドキュメントとの間のリンクを提供します。以下に段階的な内訳を示します。
-
groundingChunks: これは、モデルが参照した企業ドキュメントのリストです。各チャンクには、ドキュメントのタイトル、URI (ドキュメントパス)、およびIDが含まれています。
-
groundingSupports: このリストは、最終的な回答の特定の文を
groundingChunksに接続します。 -
segment: このオブジェクトは、
startIndex、endIndex、およびtext自体によって定義される、最終的なテキスト回答の特定の部分を識別します。 -
groundingChunkIndices: この配列には、
groundingChunksにリストされている情報源に対応するインデックス番号が含まれています。たとえば、「HIPAAコンプライアンス」に関するテキストは、インデックス1のgroundingChunksの情報 (「規制および倫理的ハードル」ドキュメント) によってサポートされています。 -
retrievalQueries: この配列は、関連情報を見つけるためにデータストアに対して実行された特定の検索クエリを示します。
Vertex AI Searchでグラウンディングされた応答を表示する方法¶
Google検索グラウンディングとは異なり、Vertex AI Searchグラウンディングは特定の表示コンポーネントを必要としません。ただし、引用とドキュメント参照を表示することで、信頼が構築され、ユーザーは組織の信頼できる情報源に対して情報を検証できます。
オプションの引用表示¶
グラウンディングメタデータが提供されているため、アプリケーションのニーズに基づいて引用表示を実装できます。
シンプルなテキスト表示 (最小限の実装):
for event in events:
if event.is_final_response():
print(event.content.parts[0].text)
# オプション: ソース数を表示
if event.grounding_metadata:
print(f"\n{len(event.grounding_metadata.grounding_chunks)}件のドキュメントに基づく")
強化された引用表示 (オプション): 各ステートメントをサポートするドキュメントを示すインタラクティブな引用を実装できます。グラウンディングメタデータは、テキストセグメントをソースドキュメントにマッピングするために必要なすべての情報を提供します。
実装に関する考慮事項¶
Vertex AI Searchグラウンディング表示を実装する場合:
- ドキュメントアクセス: 参照ドキュメントのユーザー権限を確認します
- シンプルな統合: 基本的なテキスト出力には追加の表示ロジックは必要ありません
- オプションの機能強化: ソースの帰属表示がユースケースに役立つ場合にのみ引用を追加します
- ドキュメントリンク: 必要に応じてドキュメントURIをアクセス可能な内部リンクに変換します
- 検索クエリ: retrievalQueries配列は、データストアに対して実行された検索を示します
まとめ¶
Vertex AI Searchグラウンディングは、AIエージェントを汎用アシスタントから、組織のプライベートドキュメントから正確でソース帰属表示付きの情報を提供できる企業固有の知識システムに変革します。この機能をADKエージェントに統合することで、エージェントは次のことができるようになります。
- インデックス化されたドキュメントリポジトリからの独自の情報へのアクセス
- 透明性と信頼のためのソース帰属表示の提供
- 検証可能な企業情報を含む包括的な回答の提供
- Google Cloud環境内でのデータプライバシーの維持
グラウンディングプロセスは、ユーザーのクエリを組織の知識ベースにシームレスに接続し、会話の流れを維持しながらプライベートドキュメントからの関連コンテキストで応答を豊かにします。適切に実装することで、エージェントは企業情報の発見と意思決定のための強力なツールになります。