Vertex AI 검색 기반 이해¶
Vertex AI 검색 기반 도구는 에이전트 개발 키트(ADK)의 강력한 기능으로, AI 에이전트가 개인 엔터프라이즈 문서 및 데이터 리포지토리의 정보에 액세스할 수 있도록 합니다. 에이전트를 색인된 엔터프라이즈 콘텐츠에 연결하면 조직의 지식 기반에 기반한 답변을 사용자에게 제공할 수 있습니다.
이 기능은 내부 문서, 정책, 연구 논문 또는 Vertex AI 검색 데이터 저장소에 색인된 모든 독점 콘텐츠의 정보가 필요한 엔터프라이즈별 쿼리에 특히 유용합니다. 에이전트가 지식 기반의 정보가 필요하다고 판단하면 자동으로 색인된 문서를 검색하고 적절한 출처와 함께 결과를 응답에 통합합니다.
학습 내용¶
이 가이드에서는 다음을 알아봅니다.
- 빠른 설정: Vertex AI 검색 지원 에이전트를 처음부터 만들고 실행하는 방법
- 기반 아키텍처: 엔터프라이즈 문서 기반의 데이터 흐름 및 기술 프로세스
- 응답 구조: 기반 응답 및 해당 메타데이터를 해석하는 방법
- 모범 사례: 인용 및 문서 참조를 사용자에게 표시하기 위한 지침
Vertex AI 검색 기반 빠른 시작¶
이 빠른 시작에서는 Vertex AI 검색 기반 기능이 있는 ADK 에이전트를 만드는 과정을 안내합니다. 이 빠른 시작에서는 Python 3.9 이상 및 터미널 액세스가 가능한 로컬 IDE(VS Code 또는 PyCharm 등)를 가정합니다.
1. Vertex AI 검색 준비¶
Vertex AI 검색 데이터 저장소와 해당 데이터 저장소 ID가 이미 있는 경우 이 섹션을 건너뛸 수 있습니다. 그렇지 않은 경우, 사용자 지정 검색 시작하기의 지침을 데이터 저장소 만들기 끝까지 따르되, 비정형 데이터 탭을 선택합니다. 이 지침을 통해 Alphabet 투자자 사이트의 수익 보고서 PDF가 포함된 샘플 데이터 저장소를 빌드합니다.
데이터 저장소 만들기 섹션을 마친 후 데이터 저장소를 열고 만든 데이터 저장소를 선택한 다음 데이터 저장소 ID를 찾습니다.

나중에 사용할 것이므로 이 데이터 저장소 ID를 기록해 둡니다.
2. 환경 설정 및 ADK 설치¶
가상 환경 생성 및 활성화:
# 생성
python -m venv .venv
# 활성화(각 새 터미널)
# macOS/Linux: source .venv/bin/activate
# Windows CMD: .venv\Scripts\activate.bat
# Windows PowerShell: .venv\Scripts\Activate.ps1
ADK 설치:
3. 에이전트 프로젝트 만들기¶
프로젝트 디렉터리에서 다음 명령을 실행합니다.
agent.py 편집¶
다음 코드를 복사하여 agent.py에 붙여넣고, 구성 부분의 YOUR_PROJECT_ID 및 YOUR_DATASTORE_ID를 프로젝트 ID 및 데이터 저장소 ID로 각각 바꿉니다.
from google.adk.agents import Agent
from google.adk.tools import VertexAiSearchTool
# 구성
DATASTORE_ID = "projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID"
root_agent = Agent(
name="vertex_search_agent",
model="gemini-2.5-flash",
instruction="Vertex AI 검색을 사용하여 내부 문서에서 정보를 찾아 질문에 답변합니다. 가능한 경우 항상 출처를 인용하십시오.",
description="Vertex AI 검색 기능이 있는 엔터프라이즈 문서 검색 도우미",
tools=[VertexAiSearchTool(data_store_id=DATASTORE_ID)]
)
이제 다음과 같은 디렉터리 구조가 됩니다.
4. 인증 설정¶
참고: Vertex AI 검색에는 Google Cloud Platform(Vertex AI) 인증이 필요합니다. Google AI Studio는 이 도구에서 지원되지 않습니다.
- gcloud CLI 설정
- 터미널에서
gcloud auth login을 실행하여 Google Cloud에 인증합니다. -
.env 파일을 열고 다음 코드를 복사하여 붙여넣고 프로젝트 ID와 위치를 업데이트합니다.
5. 에이전트 실행¶
에이전트와 상호 작용하는 방법에는 여러 가지가 있습니다.
다음 명령을 실행하여 개발 UI를 시작합니다.
Windows 사용자 참고
_make_subprocess_transport NotImplementedError가 발생하면 대신 adk web --no-reload를 사용해 보세요.
1단계: 제공된 URL(일반적으로 http://localhost:8000 또는 http://127.0.0.1:8000)을 브라우저에서 직접 엽니다.
2단계. UI의 왼쪽 상단 모서리에서 드롭다운에서 에이전트를 선택할 수 있습니다. "vertex_search_agent"를 선택합니다.
문제 해결
드롭다운 메뉴에 "vertex_search_agent"가 표시되지 않으면 에이전트 폴더의 상위 폴더(즉, vertex_search_agent의 상위 폴더)에서 adk web을 실행하고 있는지 확인하십시오.
3단계. 이제 텍스트 상자를 사용하여 에이전트와 채팅할 수 있습니다.
📝 시도해 볼 만한 예제 프롬프트¶
이러한 질문을 통해 에이전트가 실제로 Vertex AI 검색을 호출하여 Alphabet 보고서에서 정보를 가져오는지 확인할 수 있습니다.
- 2022년 1분기 Google Cloud의 수익은 얼마입니까?
- YouTube는 어떻습니까?

ADK를 사용하여 Vertex AI 검색 에이전트를 성공적으로 만들고 상호 작용했습니다!
Vertex AI 검색 기반 작동 방식¶
Vertex AI 검색 기반은 에이전트를 조직의 색인된 문서 및 데이터에 연결하여 개인 엔터프라이즈 콘텐츠를 기반으로 정확한 응답을 생성할 수 있도록 하는 프로세스입니다. 사용자의 프롬프트에 내부 지식 기반의 정보가 필요한 경우 에이전트의 기본 LLM은 색인된 문서에서 관련 사실을 찾기 위해 VertexAiSearchTool을 지능적으로 호출하기로 결정합니다.
데이터 흐름 다이어그램¶
이 다이어그램은 사용자 쿼리가 기반 응답을 생성하는 단계별 프로세스를 보여줍니다.
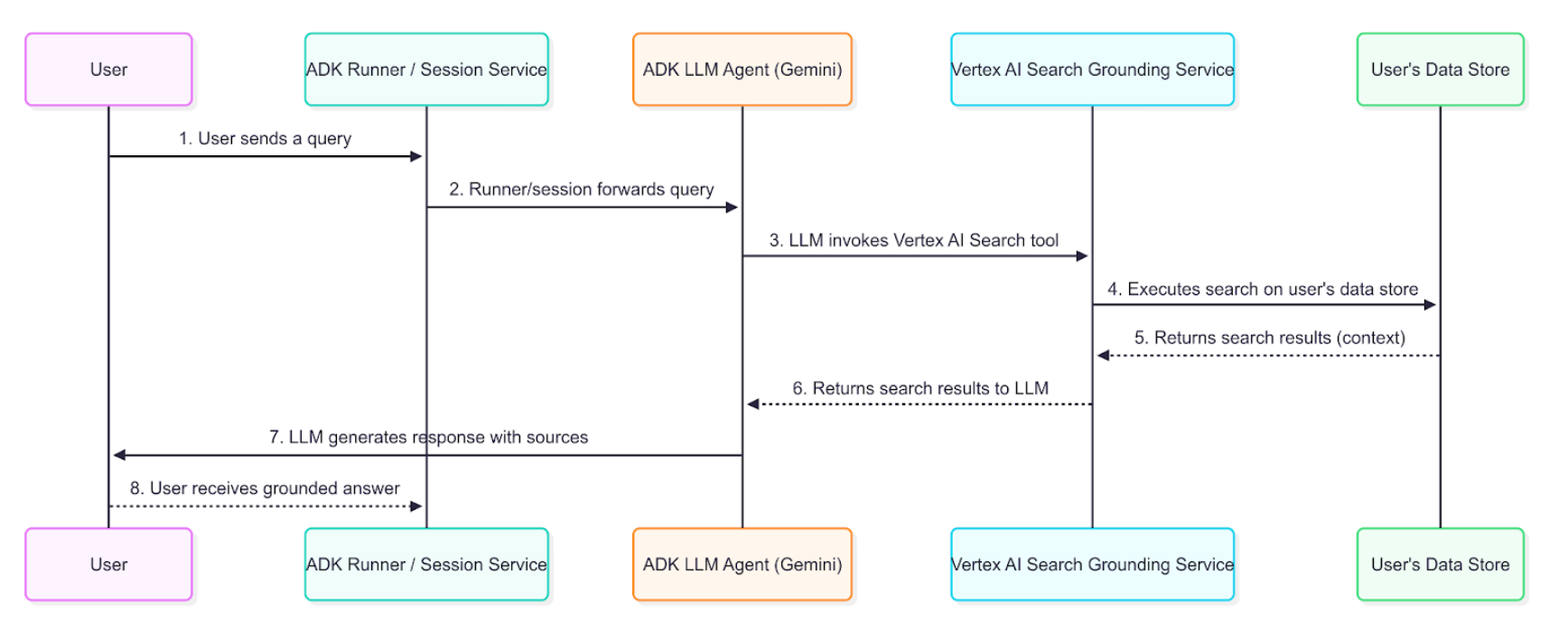
자세한 설명¶
기반 에이전트는 다이어그램에 설명된 데이터 흐름을 사용하여 엔터프라이즈 정보를 검색, 처리 및 사용자에게 제공되는 최종 답변에 통합합니다.
-
사용자 쿼리: 최종 사용자는 내부 문서 또는 엔터프라이즈 데이터에 대한 질문을 하여 에이전트와 상호 작용합니다.
-
ADK 오케스트레이션: 에이전트 개발 키트는 에이전트의 동작을 오케스트레이션하고 사용자의 메시지를 에이전트의 핵심으로 전달합니다.
-
LLM 분석 및 도구 호출: 에이전트의 LLM(예: Gemini 모델)은 프롬프트를 분석합니다. 색인된 문서의 정보가 필요하다고 판단되면 VertexAiSearchTool을 호출하여 기반 메커니즘을 트리거합니다. 이는 회사 정책, 기술 문서 또는 독점 연구에 대한 쿼리에 답변하는 데 이상적입니다.
-
Vertex AI 검색 서비스 상호 작용: VertexAiSearchTool은 색인된 엔터프라이즈 문서가 포함된 구성된 Vertex AI 검색 데이터 저장소와 상호 작용합니다. 서비스는 개인 콘텐츠에 대한 검색 쿼리를 공식화하고 실행합니다.
-
문서 검색 및 순위 지정: Vertex AI 검색은 의미적 유사성 및 관련성 점수를 기반으로 데이터 저장소에서 가장 관련성이 높은 문서 청크를 검색하고 순위를 매깁니다.
-
컨텍스트 주입: 검색 서비스는 최종 응답이 생성되기 전에 검색된 문서 스니펫을 모델의 컨텍스트에 통합합니다. 이 중요한 단계를 통해 모델은 조직의 사실 데이터를 "추론"할 수 있습니다.
-
기반 응답 생성: 이제 관련 엔터프라이즈 콘텐츠로 정보를 얻은 LLM은 문서에서 검색된 정보를 통합하는 응답을 생성합니다.
-
출처가 있는 응답 제시: ADK는 필요한 소스 문서 참조 및 groundingMetadata를 포함하는 최종 기반 응답을 수신하고 출처와 함께 사용자에게 제시합니다. 이를 통해 최종 사용자는 엔터프라이즈 출처에 대해 정보를 확인할 수 있습니다.
Vertex AI 검색 응답으로 기반 이해¶
에이전트가 Vertex AI 검색을 사용하여 응답을 기반으로 할 때 최종 텍스트 답변과 해당 답변을 생성하는 데 사용된 문서에 대한 메타데이터를 포함하는 자세한 정보를 반환합니다. 이 메타데이터는 응답을 확인하고 엔터프라이즈 출처에 대한 출처를 제공하는 데 중요합니다.
기반 응답의 예¶
다음은 엔터프라이즈 문서에 대한 기반 쿼리 후 모델에서 반환된 콘텐츠 객체의 예입니다.
최종 답변 텍스트:
"의료 서기를 위한 모델 개발은 주로 의료 문서의 복잡한 특성, 관련된 민감한 데이터 및 임상 워크플로의 까다로운 요구 사항으로 인해 몇 가지 중요한 과제를 제시합니다. 주요 과제는 다음과 같습니다. **정확성 및 신뢰성:** 의료 문서는 오류가 오진, 잘못된 치료 및 법적 파급 효과로 이어질 수 있으므로 매우 높은 수준의 정확성이 필요합니다. AI 모델이 미묘한 의료 언어를 안정적으로 캡처하고 주관적인 정보와 객관적인 정보를 구별하며 의사-환자 상호 작용을 정확하게 기록할 수 있도록 보장하는 것이 주요 장애물입니다. **자연어 이해(NLU) 및 음성 인식:** 의료 대화는 종종 빠르고 고도로 전문화된 전문 용어, 약어 및 약어를 포함하며 다양한 억양이나 말투를 가진 개인이 말할 수 있습니다... [응답은 개인 정보 보호, 통합 및 기술적 과제에 대한 자세한 분석으로 계속됩니다]"
기반 메타데이터 스니펫:
이것이 수신할 기반 메타데이터입니다. adk web에서 응답 탭에서 찾을 수 있습니다.
{
"groundingMetadata": {
"groundingChunks": [
{
"document": {
"title": "의료 서기의 AI: 기술적 과제",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-medical-scribe-ai-tech-challenges",
"id": "doc-medical-scribe-ai-tech-challenges"
}
},
{
"document": {
"title": "의료 분야 AI에 대한 규제 및 윤리적 장애물",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-ai-healthcare-ethics",
"id": "doc-ai-healthcare-ethics"
}
}
// ... 추가 문서
],
"groundingSupports": [
{
"groundingChunkIndices": [0, 1],
"segment": {
"endIndex": 637,
"startIndex": 433,
"text": "AI 모델이 미묘한 의료 언어를 안정적으로 캡처할 수 있도록 보장..."
}
}
// ... 텍스트 세그먼트를 소스 문서에 연결하는 추가 지원
],
"retrievalQueries": [
"자연어 처리 의료 분야의 과제",
"AI 의료 서기 과제",
"의료 서기를 위한 AI 개발의 어려움"
// ... 실행된 추가 검색 쿼리
]
}
}
응답 해석 방법¶
메타데이터는 모델에서 생성된 텍스트와 이를 지원하는 엔터프라이즈 문서 간의 연결을 제공합니다. 단계별 분석은 다음과 같습니다.
-
groundingChunks: 모델이 참조한 엔터프라이즈 문서 목록입니다. 각 청크에는 문서 제목, URI(문서 경로) 및 ID가 포함되어 있습니다.
-
groundingSupports: 이 목록은 최종 답변의 특정 문장을
groundingChunks에 다시 연결합니다. -
segment: 이 객체는
startIndex,endIndex및text자체로 정의된 최종 텍스트 답변의 특정 부분을 식별합니다. -
groundingChunkIndices: 이 배열에는
groundingChunks에 나열된 출처에 해당하는 인덱스 번호가 포함되어 있습니다. 예를 들어, "HIPAA 준수"에 대한 텍스트는 인덱스 1의groundingChunks("규제 및 윤리적 장애물" 문서)의 정보로 지원됩니다. -
retrievalQueries: 이 배열은 관련 정보를 찾기 위해 데이터 저장소에 대해 실행된 특정 검색 쿼리를 보여줍니다.
Vertex AI 검색으로 기반 응답을 표시하는 방법¶
Google 검색 기반과 달리 Vertex AI 검색 기반에는 특정 디스플레이 구성 요소가 필요하지 않습니다. 그러나 인용 및 문서 참조를 표시하면 신뢰를 구축하고 사용자가 조직의 신뢰할 수 있는 출처에 대해 정보를 확인할 수 있습니다.
선택적 인용 표시¶
기반 메타데이터가 제공되므로 애플리케이션 요구 사항에 따라 인용 표시를 구현하도록 선택할 수 있습니다.
간단한 텍스트 표시(최소 구현):
for event in events:
if event.is_final_response():
print(event.content.parts[0].text)
# 선택 사항: 출처 수 표시
if event.grounding_metadata:
print(f"\n{len(event.grounding_metadata.grounding_chunks)}개의 문서를 기반으로 함")
향상된 인용 표시(선택 사항): 각 문장을 지원하는 문서를 보여주는 대화형 인용을 구현할 수 있습니다. 기반 메타데이터는 텍스트 세그먼트를 소스 문서에 매핑하는 데 필요한 모든 정보를 제공합니다.
구현 고려 사항¶
Vertex AI 검색 기반 디스플레이를 구현할 때:
- 문서 액세스: 참조된 문서에 대한 사용자 권한 확인
- 간단한 통합: 기본 텍스트 출력에는 추가 디스플레이 논리가 필요하지 않습니다.
- 선택적 향상: 사용 사례가 출처 표시의 이점을 얻는 경우에만 인용 추가
- 문서 링크: 필요한 경우 문서 URI를 액세스 가능한 내부 링크로 변환
- 검색 쿼리: retrievalQueries 배열은 데이터 저장소에 대해 수행된 검색을 보여줍니다.
요약¶
Vertex AI 검색 기반은 AI 에이전트를 범용 도우미에서 조직의 개인 문서에서 정확하고 출처가 표시된 정보를 제공할 수 있는 엔터프라이즈별 지식 시스템으로 변환합니다. 이 기능을 ADK 에이전트에 통합하면 다음을 수행할 수 있습니다.
- 색인된 문서 리포지토리에서 독점 정보에 액세스
- 투명성과 신뢰를 위한 출처 표시 제공
- 검증 가능한 엔터프라이즈 사실로 포괄적인 답변 제공
- Google Cloud 환경 내에서 데이터 개인 정보 보호 유지
기반 프로세스는 사용자 쿼리를 조직의 지식 기반에 원활하게 연결하여 대화 흐름을 유지하면서 개인 문서의 관련 컨텍스트로 응답을 풍부하게 합니다. 올바르게 구현하면 에이전트는 엔터프라이즈 정보 검색 및 의사 결정을 위한 강력한 도구가 됩니다.