エージェントの検索によるグラウンディング¶
Agent Search は、AI エージェントが企業のプライベート ドキュメントやデータ リポジトリから情報にアクセスできるようにするエージェント開発キット (ADK) の強力なツールです。エージェントをインデックス付きエンタープライズ コンテンツに接続することで、組織のナレッジ ベースに基づいた回答をユーザーに提供できます。
この機能は、内部文書、ポリシー、研究論文、または Agent Search データストアでインデックス付けされている独自のコンテンツからの情報を必要とする企業固有のクエリに特に役立ちます。エージェントは、ナレッジ ベースの情報が必要であると判断すると、インデックス付きドキュメントを自動的に検索し、その結果を適切な帰属とともに応答に組み込みます。
エージェント検索の準備¶
固定エージェントを作成する前に、既存のエージェント検索データ ストアが必要です。お持ちでない場合は、Get started with custom search の手順に従って作成してください。エージェントを設定するには、Data store ID (例: projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID) が必要です。
認証のセットアップ¶
注: エージェントの検索には、Google Cloud Platform (エージェント プラットフォーム) 認証が必要です。 Google AI Studio はこのツールではサポートされていません。
- gcloud CLI をセットアップします。
- 端末から
gcloud auth loginを実行して、Google Cloud に対して認証します。 - Python の場合、
.envファイルを開き、プロジェクト ID と場所を指定します。 - Java の場合、アプリケーション環境に Google Cloud のデフォルト認証情報が設定されていることを確認してください (
GOOGLE_APPLICATION_CREDENTIALS)。
GOOGLE_GENAI_USE_VERTEXAI=TRUE
GOOGLE_CLOUD_PROJECT=YOUR_PROJECT_ID
GOOGLE_CLOUD_LOCATION=LOCATION
グラウンデッド エージェントの作成¶
検索によるグラウンディングを有効にするには、エージェント定義に検索ツールを含めて、data_store_id を提供します。
from google.adk.agents import Agent
from google.adk.tools import VertexAiSearchTool
# Configuration
DATASTORE_ID = "projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID"
root_agent = Agent(
name="vertex_search_agent",
model="gemini-flash-latest",
instruction="Answer questions using Agent Search to find information from internal documents. Always cite sources when available.",
description="Enterprise document search assistant with Agent Search capabilities",
tools=[VertexAiSearchTool(data_store_id=DATASTORE_ID)]
)
import com.google.adk.agents.LlmAgent;
import com.google.adk.tools.VertexAiSearchTool;
// Configuration
String DATASTORE_ID = "projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID";
LlmAgent rootAgent = LlmAgent.builder()
.name("vertex_search_agent")
.model("gemini-flash-latest")
.instruction("Answer questions using Agent Search to find information from internal documents. Always cite sources when available.")
.description("Enterprise document search assistant with Agent Search capabilities")
.tools(VertexAiSearchTool.builder().dataStoreId(DATASTORE_ID).build())
.build();
検索によるグラウンディングの仕組み¶
検索によるグラウンディングは、エージェントを組織のインデックス付きドキュメントおよびデータに接続するプロセスであり、民間の企業コンテンツに基づいて正確な応答を生成できるようになります。ユーザーのプロンプトで内部ナレッジ ベースからの情報が必要な場合、エージェントの基盤となる LLM は VertexAiSearchTool を呼び出して、インデックス付けされたドキュメントから関連する事実を見つけることをインテリジェントに決定します。
データフロー図¶
この図は、ユーザーのクエリが根拠のある応答をもたらすプロセスを段階的に示しています。
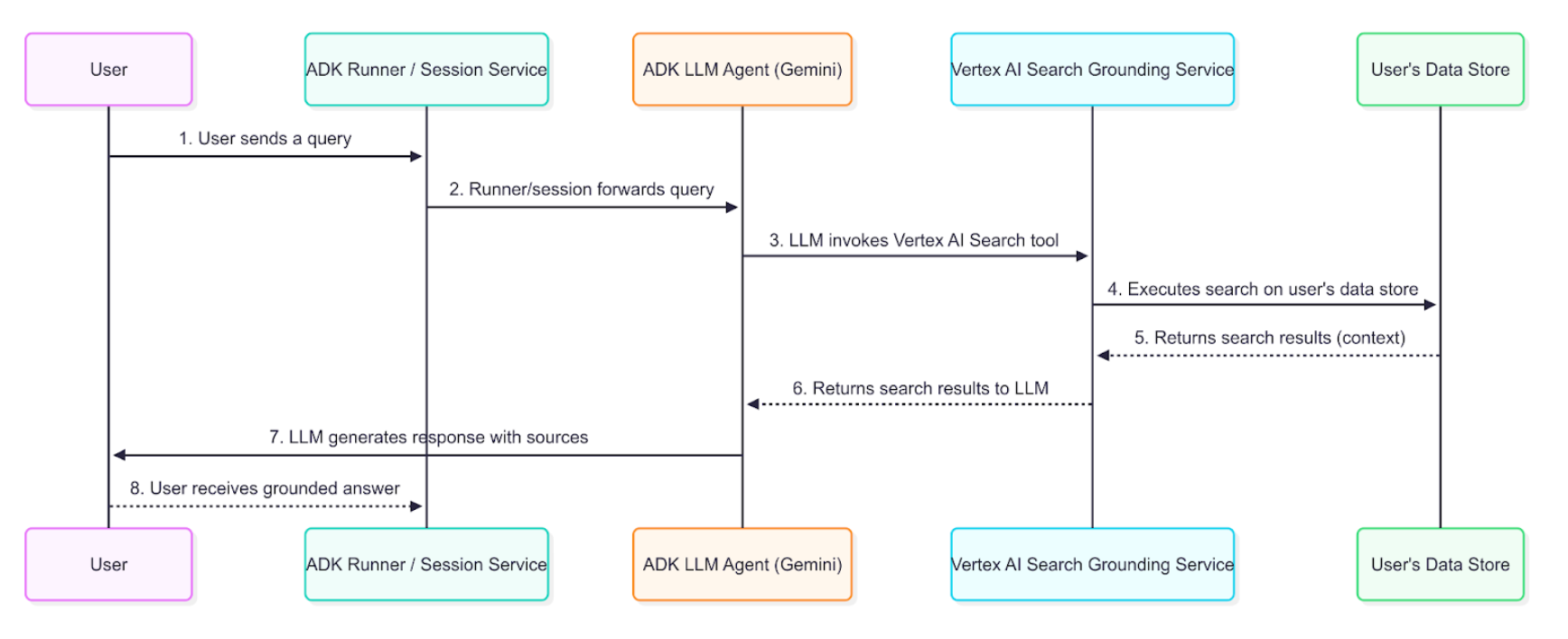
詳細な説明¶
グラウンディング エージェントは、図で説明されているデータ フローを使用して、企業情報を取得、処理し、ユーザーに提示される最終的な回答に組み込みます。
- ユーザー クエリ: エンドユーザーは、内部文書または企業データに関する質問をすることでエージェントと対話します。
- ADK オーケストレーション: エージェント開発キットは、エージェントの動作を調整し、ユーザーのメッセージをエージェントのコアに渡します。
- LLM 分析とツール呼び出し: エージェントの LLM (Gemini モデルなど) がプロンプトを分析します。インデックス付きドキュメントの情報が必要であると判断した場合、
VertexAiSearchToolを呼び出してグラウンディング メカニズムをトリガーします。これは、会社のポリシー、技術文書、または独自の研究に関する質問に答えるのに最適です。 - Vertex AI Search サービスの対話:
VertexAiSearchToolは、インデックス付けされたエンタープライズ ドキュメントを含む構成済みの Agent Search データストアと対話します。このサービスは、プライベート コンテンツに対する検索クエリを作成して実行します。 - ドキュメントの取得とランキング: Agent Search は、セマンティックな類似性と関連性スコアに基づいて、データストアから最も関連性の高いドキュメント チャンクを取得し、ランク付けします。
- コンテキスト インジェクション: 検索サービスは、最終応答が生成される前に、取得したドキュメント スニペットをモデルのコンテキストに統合します。この重要なステップにより、モデルは組織の事実データを「推論」できるようになります。
- 根拠のある応答の生成: LLM は、関連する企業コンテンツからの情報を受けて、ドキュメントから取得した情報を組み込んだ応答を生成します。
- ソース付きの応答表示: ADK は、必要なソース文書参照と
groundingMetadataを含む最終的な根拠のある応答を受信し、帰属とともにユーザーに表示します。これにより、エンドユーザーは企業のソースと照合して情報を検証できるようになります。
検索応答によるグラウンディングを理解する¶
エージェントが Agent Search を使用して応答を確定すると、最終的なテキスト応答と、その応答の生成に使用されたドキュメントに関するメタデータを含む詳細情報が返されます。このメタデータは、応答を検証し、企業ソースへの帰属を提供するために重要です。
根拠のある応答の例¶
以下は、企業ドキュメントに対する根拠のあるクエリの後にモデルによって返されるコンテンツ オブジェクトの例です。
最終回答テキスト:
"Developing models for a medical scribe presents several significant challenges, primarily due to the complex nature of medical documentation, the sensitive data involved, and the demanding requirements of clinical workflows. Key challenges include: **Accuracy and Reliability:** Medical documentation requires extremely high levels of accuracy, as errors can lead to misdiagnoses, incorrect treatments, and legal repercussions. Ensuring that AI models can reliably capture nuanced medical language, distinguish between subjective and objective information, and accurately transcribe physician-patient interactions is a major hurdle. **Natural Language Understanding (NLU) and Speech Recognition:** Medical conversations are often rapid, involve highly specialized jargon, acronyms, and abbreviations, and can be spoken by individuals with diverse accents or speech patterns... [response continues with detailed analysis of privacy, integration, and technical challenges]"
グラウンディングメタデータスニペット:
{
"groundingMetadata": {
"groundingChunks": [
{
"document": {
"title": "AI in Medical Scribing: Technical Challenges",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-medical-scribe-ai-tech-challenges",
"id": "doc-medical-scribe-ai-tech-challenges"
}
},
{
"document": {
"title": "Regulatory and Ethical Hurdles for AI in Healthcare",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-ai-healthcare-ethics",
"id": "doc-ai-healthcare-ethics"
}
}
],
"groundingSupports": [
{
"groundingChunkIndices": [0, 1],
"segment": {
"endIndex": 637,
"startIndex": 433,
"text": "Ensuring that AI models can reliably capture nuanced medical language..."
}
}
],
"retrievalQueries": [
"challenges in natural language processing medical domain",
"AI medical scribe challenges",
"difficulties in developing AI for medical scribes"
]
}
}
応答の解釈方法¶
メタデータは、モデルによって生成されたテキストとそれをサポートする企業ドキュメントの間のリンクを提供します。段階的な内訳は次のとおりです。
- groundingChunks: これは、モデルが参照した企業文書のリストです。各チャンクには、ドキュメント
title、uri(ドキュメント パス)、およびidが含まれています。 - groundingSupports: このリストは、最終回答の特定の文を
groundingChunksに結び付けます。 - セグメント: このオブジェクトは、
startIndex、endIndex、およびtext自体によって定義される、最終的なテキスト回答の特定の部分を識別します。 - groundingChunkIndices: この配列には、
groundingChunksにリストされているソースに対応するインデックス番号が含まれています。たとえば、「HIPAA 準拠」に関するテキストは、インデックス 1 のgroundingChunksの情報 (「規制と倫理のハードル」文書) によってサポートされています。 - retrievalQueries: この配列は、関連情報を見つけるためにデータストアに対して実行された特定の検索クエリを示します。
Grounding with Search で応答を表示する方法¶
Google 検索のグラウンディングとは異なり、検索によるグラウンディングには特定の表示コンポーネントは必要ありません。ただし、引用や文書参照を表示すると信頼が構築され、ユーザーが組織の信頼できる情報源と照合して情報を検証できるようになります。
オプションの引用表示¶
根拠となるメタデータが提供されるため、アプリケーションのニーズに基づいて引用表示の実装を選択できます。
単純なテキスト表示 (最小限の実装):
for (Event event : events) {
if (event.finalResponse()) {
System.out.println(event.content().parts().get(0).text());
// Optional: Show source count
if (event.groundingMetadata().isPresent()) {
System.out.println("\nBased on " + event.groundingMetadata().get().groundingChunks().size() + " documents");
}
}
}
引用表示の強化 (オプション): どの文書が各ステートメントをサポートしているかを示すインタラクティブな引用を実装できます。グラウンディング メタデータは、テキスト セグメントをソース ドキュメントにマッピングするために必要なすべての情報を提供します。
実装に関する考慮事項¶
検索を使用してグラウンディングを実装すると、次の表示が表示されます。
- ドキュメント アクセス: 参照ドキュメントに対するユーザー権限を確認します。
- シンプルな統合: 基本的なテキスト出力には追加の表示ロジックは必要ありません
- オプションの機能拡張: ユースケースがソースの帰属から恩恵を受ける場合にのみ引用を追加します。
- ドキュメント リンク: 必要に応じて、ドキュメント URI をアクセス可能な内部リンクに変換します。
- 検索クエリ:
retrievalQueries配列は、データストアに対して実行された検索を示します。